
구조화 데이터 스키마 마크업(Schema Markup)이란?
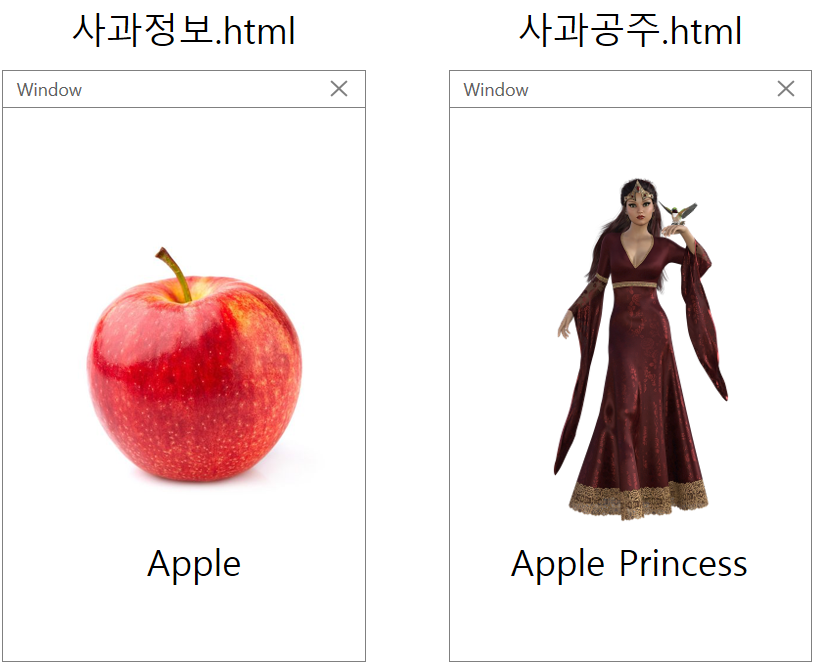
사과 공주가 사과가 된다면?
만약 아래와 같이 사과 정보, 사과 공주에 대한 정보를 담고 있는 페이지가 있다고 가정해 본다면, 사람의 눈으로 보면 당연히 하나의 페이지는 사과에 대한 정보를 담은 페이지로 다른 하나는 공주에 대한 페이지로 인식할 것입니다. 하지만 검색엔진이 이해하는 언어는 사람의 언어와 다르기 때문에 별도의 설명이 없으면 둘 다 사과에 대한 정보 페이지로 인식할 수도 있습니다. 물론 메타 정보나 콘텐츠 내용 상에 명확하게 정의가 되어 있다면 검색엔진이 콘텐츠의 내용을 파악하는데 큰 어려움이 없겠지만 그런 경우가 아니라면 우리가 의도하지 않게 검색엔진이 페이지를 이해할 수도 있습니다.
검색결과에 좀 더 많은 정보를 담을 수 있다면?
구글 검색엔진에 “떡볶이 만드는 법”이라고 검색하면 수 없이 많은 검색 결과가 출력됩니다. 그런데 일반적인 검색결과와 다르게 아래 이미지 파란색 테두리로 처리된 부분을 보면 평점, 평점 개수, 리뷰 등 검색엔진이 어떻게 알았을까 하는 내용까지 출력되는 것을 볼 수 있습니다.
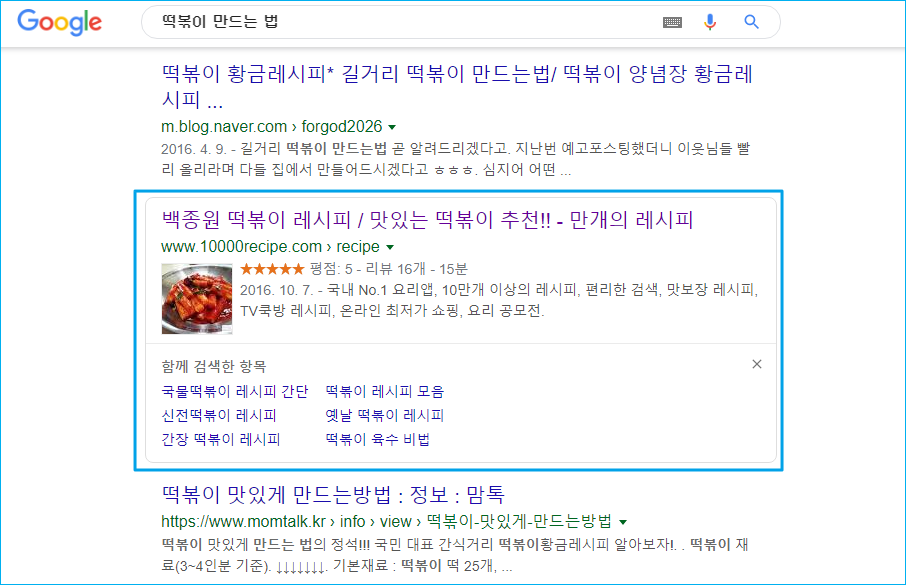
구조화된 데이터 (structured data) 란? 다양한 정보를 담고 있는 콘텐츠를 논리적으로 조직화하여 제공함으로써 검색엔진 입장에서 페이지를 쉽게 이해하고 더 많은 정보(리치 스니펫) 를 수집할 수 있도록 돕는 역할을 합니다.
콘텐츠에 구조화된 데이터를 제공할 경우 위와 같이 더 풍부한 검색 결과를 제공할 수 있으며 이는 검색을 하는 사용자들이 해당 사이트를 선택하게 할 확률을 높여줄 수 있습니다.
구조화된 데이터(structured data)는 어떻게 작성하는가?
schema.org
2011년 6월 2일 google. bing, yahoo 등 당시 세계 최대 검색 엔진 운영자들이 모여 웹 페지이에서 구조화된 데이터 마크 업을 위한 공통 스키마 작성을 위한 schema.org를 발표합니다. Schema.org는 웹페이지의 정보를 구조화해서 검색엔진이 더 정확하게 분석할 수 있게 한 것으로 그 안에는 다양한 명세가 포함되어 있습니다.
즉, 구조화된 데이터 작업을 위해서는 schema.org에서 제공하는 타입(type)과 속성(property)값을 이용하여 제작할 수 있습니다.
구조화된 데이터 제작을 위한 언어 형식
schema.org를 활용하여 구조화된 데이터 작업 시 Microdata와 RDFa, JSON-LD의 세 가지 언어 형식을 지원합니다. 구글과 네이버의 경우 JSON-LD 형식을 권장하기 때문에 가급적 해당 언어를 이용하여 구조화된 데이터 작업을 진행하는 것이 좋습니다.
- JSON-LD(권장) : 페이지 헤드 또는 본문의 태그 내에 삽입되는 자바스크립트 표기입니다.
//JSON-LD 형식
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Person",
"name": "My Site Name",
"url": "http://www.mysite.com",
"sameAs": [
"https://www.facebook.com/myfacebook",
"http://blog.naver.com/myblog",
"http://storefarm.naver.com/mystore"
]
}
</script>- Microdata(마이크로데이타) : HTML 콘텐츠 내에 구조화된 데이터를 사용되는 개방형 커뮤니티 HTML 사양입니다. RDFa와 같이 HTML 태그 속성을 사용해 구조화된 데이터로 표시하려는 속성의 이름을 지정합니다. 대개 페이지 본문에 사용되지만 헤드에 사용될 수도 있습니다.
<span itemscope="" itemtype="http://schema.org/Organization">
<link itemprop="url" href="http://www.mysite.com">
<a itemprop="sameAs" href="https://www.facebook.com/myfacebook"></a>
<a itemprop="sameAs" href="http://blog.naver.com/myblog"></a>
<a itemprop="sameAs" href="http://storefarm.naver.com/mystore"></a>
</span>예시를 통한 구조화된 데이터 작성 및 동작원리
레시피 사이트에서 구조화된 데이터 사용 예시
위 예시처럼 구글에서 “떡볶이 만드는 법”을 검색하여 구조화된 데이터가 적용되었다고 예상되는 사이트에 접속한 후 소스 보기를 하면 아래와 같이 구조화된 데이터가 JSON-LD 양식으로 적용된 것을 확인할 수 있습니다.
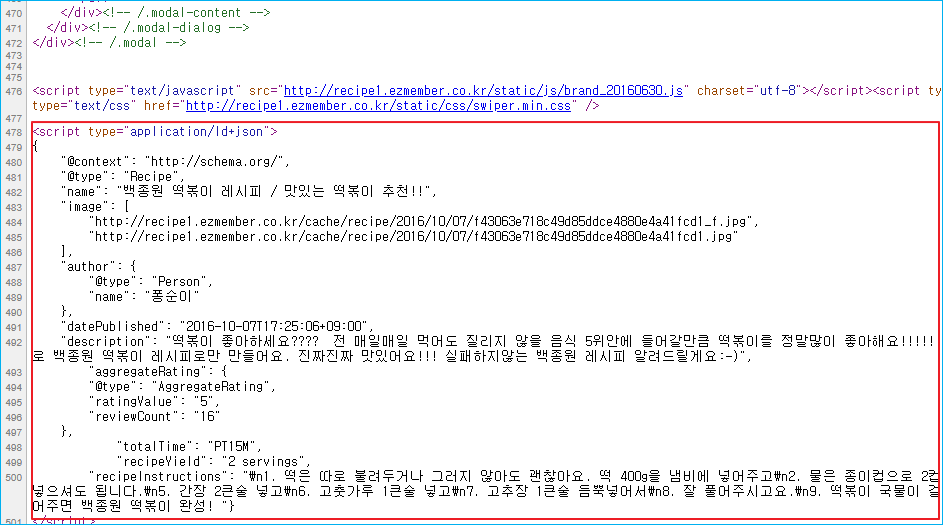
실질적으로 사용자들에게는 아래처럼 떡볶이 이미지에 레시피 정보로만 보이겠지만 검색엔진의 관점에서 보면 위의 소스 예시처럼 구조화된 데이터를 참조하여 해당 페이지에서 다양한 정보를 수집하여 사용자에게 더욱 정확하고 풍부한 정보를 제공할 수 있게 됩니다.
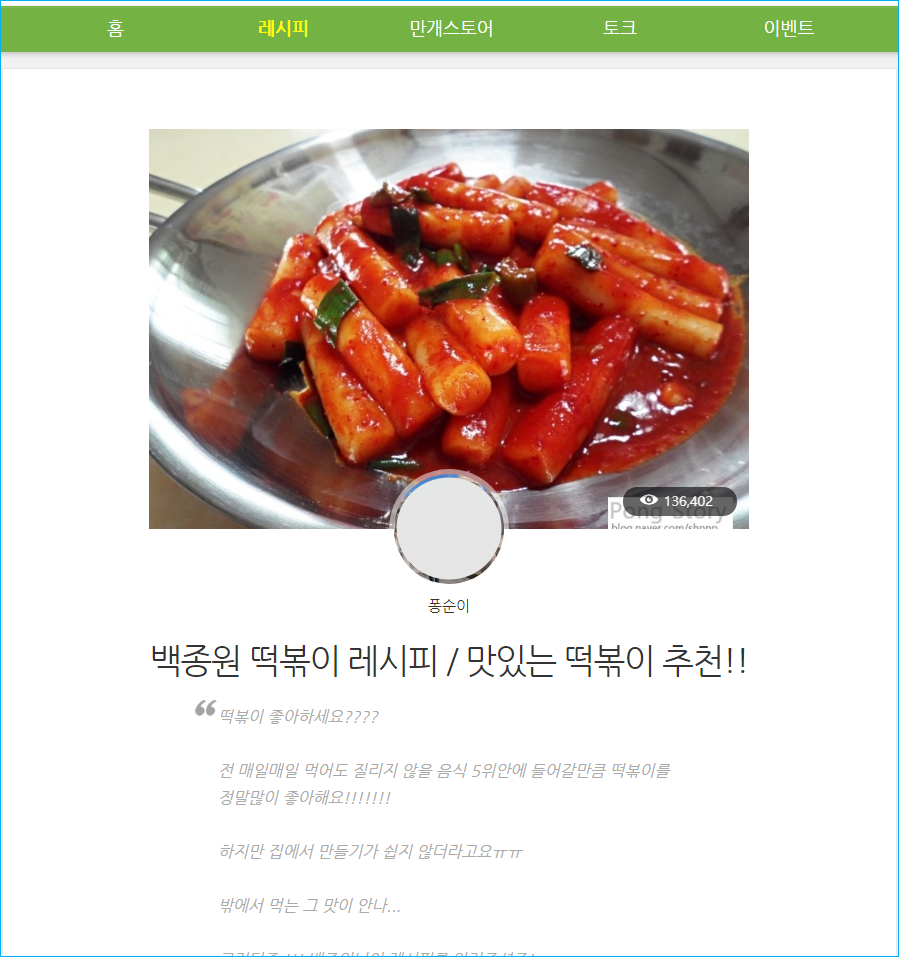
그러면 위의 예시처럼 레시피 사이트를 운영한다고 가정했을 때 구조화된 데이터 작성법에 대해 알아보도록 하겠습니다.
1.schema.org에 접속합니다.
2.아래 이미지처럼 상단 검색 입력창에 recipe라고 검색합니다. 검색 결과에 recipe를 클릭합니다.
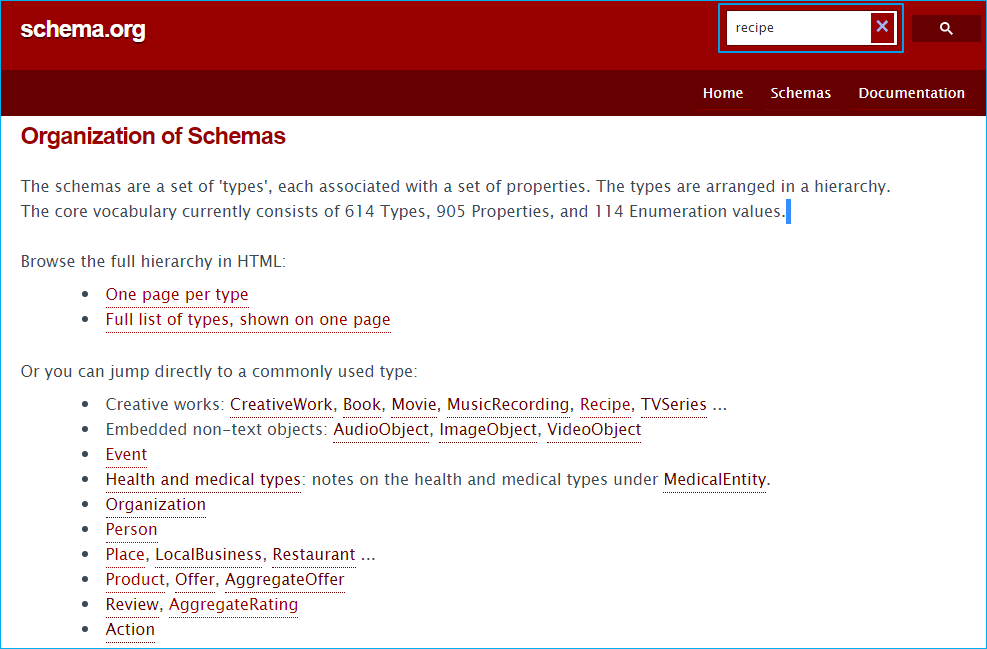
구조화된 데이터 작업을 위해서는 타입(type)과 속성(property)값을 정의한다고 했었는데요 여기서 recipe는 타입(유형)이 되는 것입니다. 타입은 Person. Product,Organization 등 다양한 유형이 있기때문에 페이지 특성에 맞게 지정하면 됩니다. 저희는 레시피를 위한 구조화된 데이터 작업이기 때문에 유형은 recipe로 지정하시면 됩니다.
3. 타입(type)을 클릭하면 타입에 소속된 속성(property) 값들을 볼 수 있습니다. 아래처럼 recipe타입에 소속된 속성 값들이 정의되어 있습니다. 각 속성별로 어떤 포맷으로 작성해야 하는지는 Expected Type을 참조하시면 됩니다.
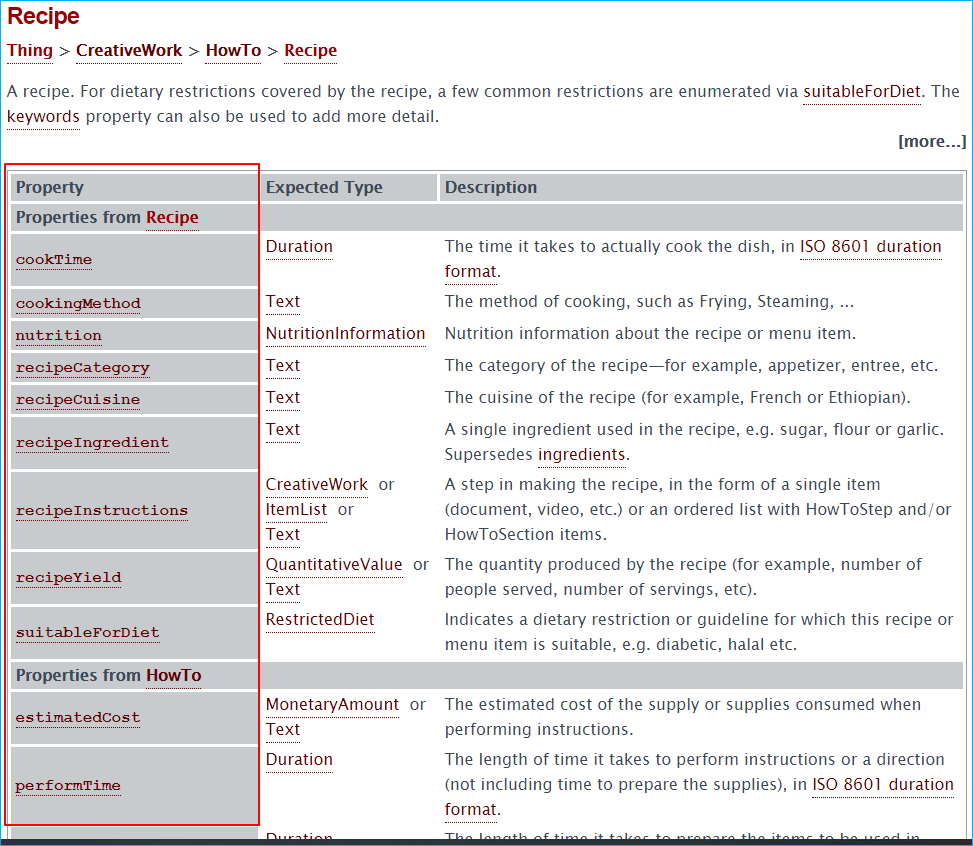
4. 위의 떡볶이 레시피 페이지를 구조화된 데이터로 작업하면 아래와 같이 됩니다. 속성 값들은 자신의 페이지 특성에 맞춰 추가하거나 삭제해도 무방하며 개발자가 아닌 경우에는 구조화된 데이터를 만들기가 어렵기 때문에 잘 된 사이트 또는 구조화된 데이터 예시 소스를 활용하여 자신의 사이트에 맞게 수정하여 사용하시길 권장드립니다.
아래 소스 주석 부분을 참고하시면서 구조를 파악해 보시면 내용을 이해 하시는데 큰 무리가 없을 것으로 판단됩니다.
<script type="application/ld+json">
{
"@context": "http://schema.org/", //컨텍스트 선언(필수)
"@type": "Recipe", //타입 : 페이지 특성에 맞게 설정
"name(속성)": "백종원 떡볶이 레시피 맛있는 떡볶이 추천!!", //페이지 제목
"image(속성)": [
"http://recipe1.ezmember.co.kr/cache/recipe/2016/10/07/f43063e718c49d85ddce4880e4a41fcd1_f.jpg", //페이지에서 사용한 이미지1
"http://recipe1.ezmember.co.kr/cache/recipe/2016/10/07/f43063e718c49d85ddce4880e4a41fcd1.jpg" //페이지에서 사용한 이미지1
],
"author(속성)": { //등록자정보 , 하나의 속성 안에는 또다른 타입이 들어갈 수 있음
"@type": "Person", //속성에 포함된 타입
"name(속성)": "퐁순이" //등록자
},
"datePublished(속성)": "2016-10-07T17:25:06+09:00", //등록일시
"description(속성)": "떡볶이 좋아하세요???? 전 매일매일 먹어도 질리지 않을 음식 5위안에 들어갈만큼 떡볶이를 정말많이 좋아해요!!!!!!! 하지만 집에서 만들기가 쉽지 않더라고요ㅠㅠ 밖에서 먹는 그 맛이 안나... 그러던중 !!! 백종원님이 레시피를 알려주셨죠! 만들어 먹어본뒤로 백종원 떡볶이 레시피로만 만들어요. 진짜진짜 맛있어요!!! 실패하지않는 백종원 레시피 알려드릴게요:-)", //상세설명
"aggregateRating": {
"@type": "AggregateRating", //등급 유형
"ratingValue(속성)": "5", //평가점수
"reviewCount(속성)": "16" //리뷰 숫자
},
"totalTime(속성)": "PT15M", //조리시간
"recipeYield(속성)": "2 servings", //인분
"recipeInstructions(속성)": "\n1. 떡은 따로 불려두거나 그러지 않아도 괜찮아요. 떡 400g을 냄비에 넣어주고\n2. 물은 종이컵으로 2컵 넣어주세요.\n3. 자작하게 잠길정도의 양이에요.\n4. 설탕 4큰술 넣고, 백종원님은 설탕 4큰술이라했는데 단거 별로안좋아하시는분은 2-3큰술 넣으셔도 됩니다.\n5. 간장 2큰술 넣고\n6. 고춧가루 1큰술 넣고\n7. 고추장 1큰술 듬뿍넣어서\n8. 잘 풀어주시고요.\n9. 떡볶이 국물이 걸죽해지도록 보글보글 끓여주세요.\n10. 준비해둔 파를 1컵 넣어주세요.\n11. 물이 많이 졸았죠?!\n12. 물이 어느정도 자작해지면 한번 휘리릭 섞어주면 백종원 떡볶이 완성! "} //레시피 상세
</script>5. 위와 같이 구조화된 데이터 작업이 완료되면 적용을 원하는 페이지 head나 body에 위 소스를 붙여 넣으면 됩니다. 데이터 작업이 정확이 되었는지를 검토하려면 구글에서 제공하는 테스팅 도구를 활용하시면 됩니다.
구조화된 데이터 테스트 도구 바로가기
구조화된 데이터 작업은 복잡해 보이지만 실제로 적용해 보면 어려운 작업은 아닙니다. 그리고 구조화된 데이터 작업을 한다고 해서 검색엔진에 검색결과가 표시된다는 보장은 없습니다. 하지만 SEO작업은 하루 아침에 되는 작업이 아니므로 신규 콘텐츠를 업데이트할 때마다 페이지에서 제공하고자 하는 정보를 검색엔진이 좀 더 확실히 파악할 수 있도록 구조화된 데이터 작업을 하는 것이 좋다고 생각됩니다.